

Working incrementally, you'll write tests, the AI will write code to pass them. All the kit you need is accessible in the browser.
In this workshop, we assume that code is cheap, that testing is human, and that the best way to get value out of generative AI is to use it as a tool for our minds. Generative AIs are a novel way to collaborate with (stand on the shoulders of) all the other people whose content has been ingested.
We hope you'll find this as compelling and weird and powerful as we do.
Outline
We're running on Wednesday from 14:45 p.m. – 16:45, with a break in the middle. We're in D1+D2.
We'll get hands-on within the first 10 minutes, and aim that the group shares useful perspectives in the last 15 minutes of the workshop. You'll spend over an hour working through exercises. Bart and James will guide and help.
First half – 14:45 to 15:30: We'll give you the briefest of introductions to writing tests before code, and show you round your working environment: Replit. We'll give you the instructions that you need to change tests and send those tests to an AI with our script, talk you through the script, and show you a short worked example. You'll gather in small groups and work together to write tests, generate code, and explore what you get. We expect to get through exercises 0, 1 and 2 /3 before the break, and might start 4 / 5.
Break – 15:30 to 16:15: You're welcome to keep working over the break, to take a moment and return as the sessions start – or to leave. You're also welcome to drop in for the second half; we'll help you set up, and you should find plenty of information on this page.
Second half – 16:00-16:45: We'll take a moment to hear from anyone with something to share, then keep on with the more freeform exercises 4 / 5, working towards stuff to share at the end. We'll get you ready to share about 20 minutes before the end of the session.
End: You'll have guided an AI to write code that passes your tests. You'll have built incrementally towards something that might not be generated in one go – and seen how the generated code changed. You'll have read generated code or explored the resulting systems, you'll have fiddled with the prompts. You'll have worked with others in the group – and maybe you'll carry on playing with these your new colleagues!
Abstract: Guiding Hands-off AI using Hands-on TDD
What can an AI build when guided by examples? What can we build as we iterate? What can we discover about what's been built?
In this hands-on workshop, you’ll write tests, and an AI will write the code.
We’ll give you a zero-install environment with a simple unit testing framework, and an AI that can parse that framework. You’ll add to the tests, run the harness to see that they fail, then ask the AI to write code to make them pass. You’ll look at the code, ask for changes if it seems necessary, incorporate that code and run the tests for real. You’ll explore to find unexpected behaviours, and add tests to characterise those failures – or to expand what your system does. As you add more tests, the AI will make more code. Maybe you’ll pause to refactor the code within your tests.
Bart and James are exploring the different technologies and approaches that make this possible. We’ll bring worked examples, different test approaches, and enough experience (we hope) to help you to work towards insights that are relevant to you. All you need to bring are a laptop (or competent tablet) and an enquiring mind. You’ll take away direct experience of co-building code with an AI, and of finding problems in AI-coded systems. We hope that you’ll learn the power and the pitfalls of working in this way – and you'll see how we worked together to find out for ourselves.
Materials, kit and tools
Detailed materials are all on this page.
You'll need something that is connected to the internet, that you can use to type.
If you need a shared resource, we have a Miro board for this workshop. You can edit it now, and we'll lock it after the workshop so that you can refer to it.
Using your kit and browser of choice, you will: use Replit as your IDE, write Python test code with a TDD approach, run bash scripts, test using Pytest, connect to AIs with llm, generate code with AIs Claude 3.5 Sonnet and GPT-4o mini, and use git for change control.
More about the moving parts
There's a hopeless learning curve to doing all this in a conference session, which is why we've done some of it for you.
On your machine, you'll work in Replit via your browser. Replit puts a pre-configured cloud-based dev environment in your browser, allowing access to the command line, to the file system, to libraries and to change control.
We'll write tests in Python using PyTest as a test harness, and PyCov / coverage for coverage metrics.
We'll use the command line tool llm as a universal API to a code-generating cloud AI, with templates containing the prompts for the AI, and we'll use a command line script to wrap AI interactions in validation, automated tests, iteration and change control. Change control is via git in Replit, and can be linked to github.
We'll use Anthropic's Claude 3.5 Sonnet or OpenAI's GPT 4o-mini to generate code – with prompts held as llm templates.
The shell scripts and prompts are by James, and are yours to change / use as you wish.
You'll find specifics and instructions below.
Using Replit
Here's Replit's own set of videos .
Replit's UI: basics
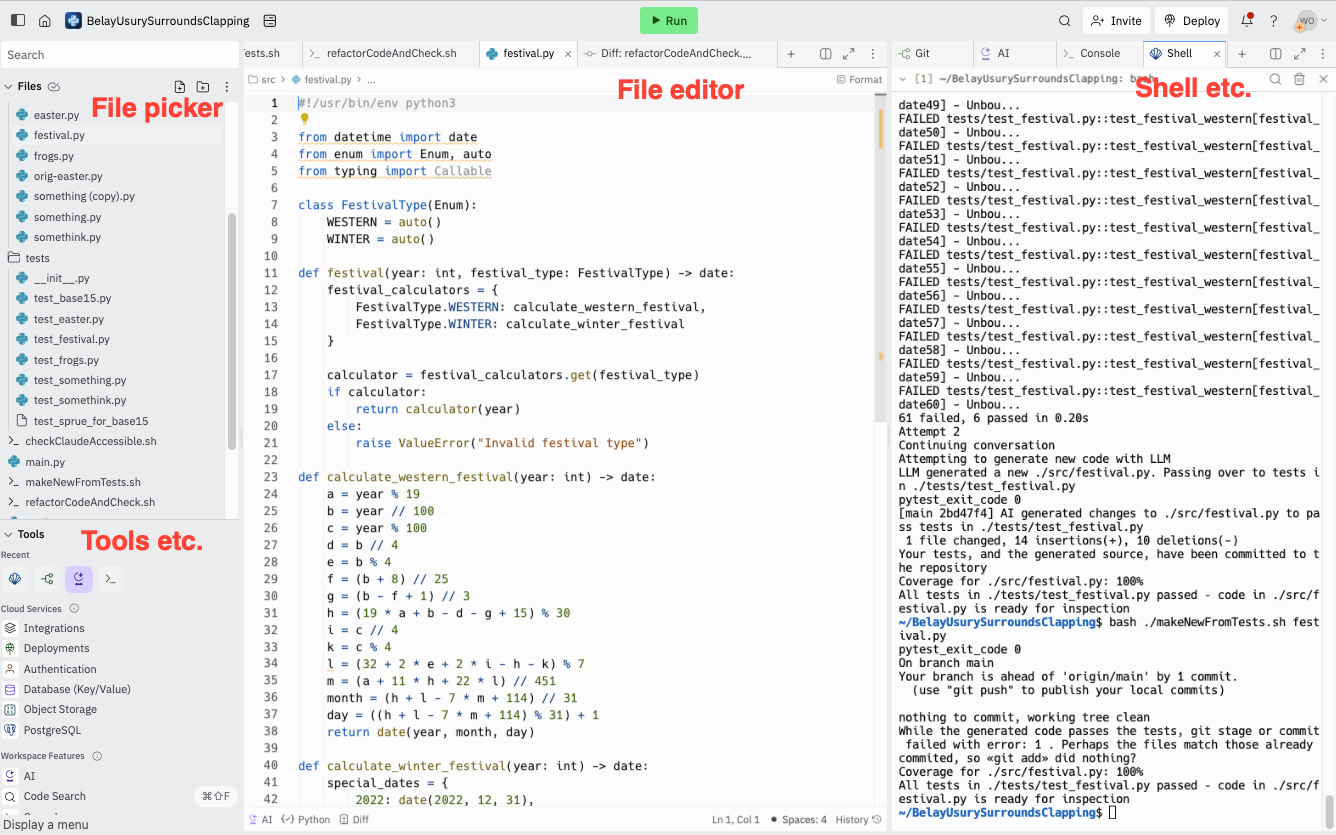
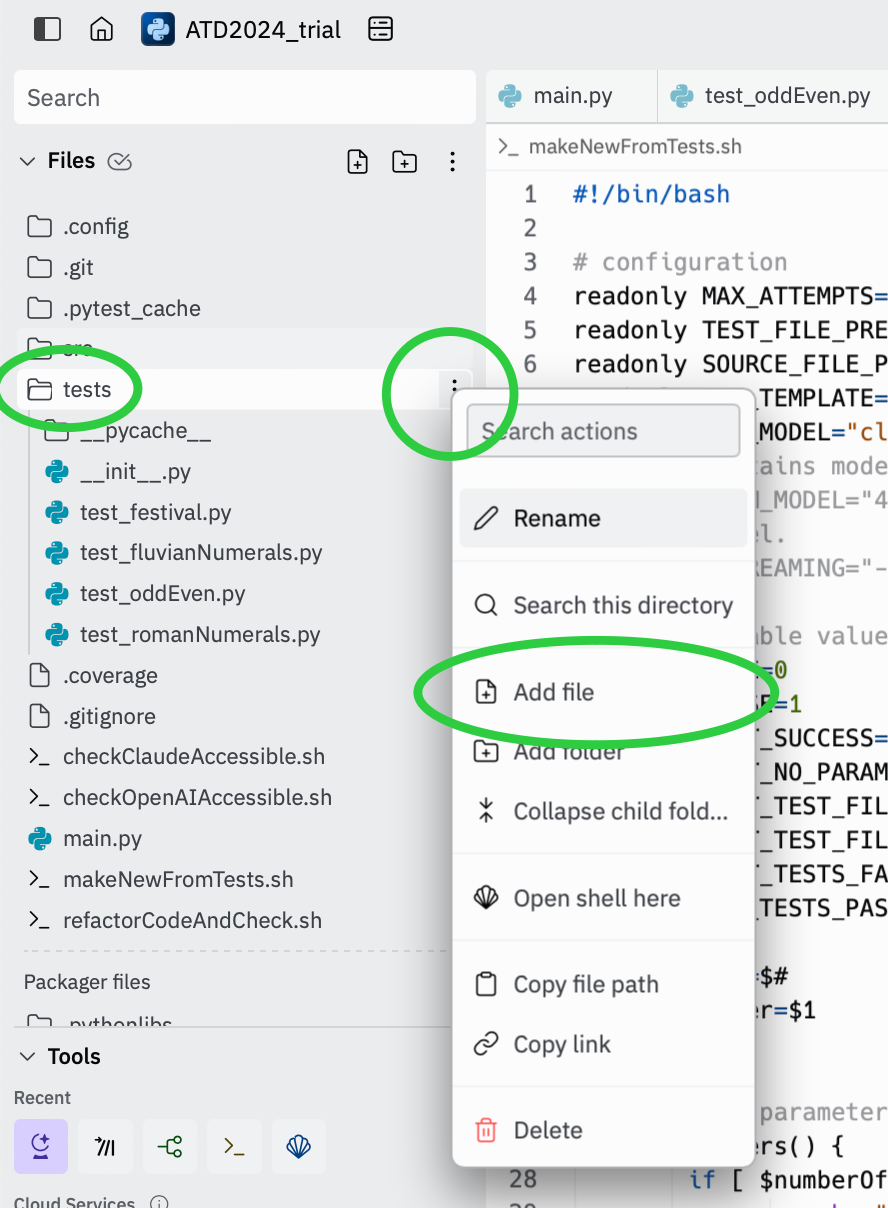
Making a file – use the context menu by the folder you want to make the file in, This is making a new file in the ./tests directory.
Use the 'history' button (editing pane, bottom right) to go back and forth through your changes. Particularly useful to take a file back to the previous version without needing to trouble git.

Use the Shell tab to get a commandline.
To actually run your python script: set something up in main.py to run whatever script you're working on, and hit the green Run button. There's already something in main.py to give access to oddEven.py and fluvianNumerals.py and festival.py.

TDD in ~50 words
Start with something that can swiftly and deterministically test something else.
Add one small test that demonstrably fails. [RED]
Build minimal code immediately to make that test pass.
Run the tests. Check that they all pass. [GREEN]
Repeat.
Sort out the code, running tests and checking that the tests still pass. [REFACTOR]
For this workshop, we've given you an environment that can swiftly and deterministically test. You add a test that fails, and trigger the tests. An AI generates code, the tests run again, and the AI tries again the tests fail. Then you explore what it's made, and add another test.
Using llm
llm is a CLI utility and Python library for interacting with LLMs by Simon Willison. Find it on GitHub:LLM, read about it on LLM's site.
Handy commands:
llm --help
llm templates --help
to see templates llm templates list
to edit a template on the comand-line use llm templates edit «template name», or edit it in Replit's visual editor by browsing and opening (generally) ~/.config/io.datasette.llm/templates
to change editor export EDITOR=vim
to see the commands sent llm logs
You're using James's keys. They're temporary, and will stop working after the workshop. Add your own model (and your own key) with llm keys set openai, llm keys set claude, llm keys set mistral then pasting in your key.
Using the shell
Hit up arrow to see / edit recent commands (and return to submit)
Hit escape twice to (generally) auto-complete
Change editor with export EDITOR=vim
Run a script with ./«scriptname» . We've seen problems occasionally with bash «scriptname».
Using the script
Use ./makeNewFromTests.sh «target code file name» .
Note «target code file name» is the name of the file you want to generate: if you want to generate src/stuff.py, you'll edit tests/test_stuff.py and run ./makeNewFromTests.sh test_stuff.py
This will:
- make a new, empty
oddEven.py, - run the tests (which fail),
- generate code from the tests and test results. It would typically pay attention to the code, but there's no code at this stage.
- run the tests (which pass),
- commit both code and test files and...
- exit.
See "under the hood" for structure and code.
The script produces lots of output: it tells you what it's doing, and shares output from pytest and git. Here's an annotated example.
COMMAND
./makeNewFromTests.sh oddEven.py
MAKE SOURCE (this time)
Source file ./src/oddEven.py does not exist. Creating an empty file.
RUN TESTS (info from pytest)
Running tests (checks) from ./tests/test_oddEven.py
Pytest exited with: 2
Tests failed. Test output follows<<<<<<<<<<
==================================== ERRORS ====================================
____________________ ERROR collecting tests/test_oddEven.py ____________________
ImportError while importing test module '/home/runner/ATD2024trialjl/tests/test_oddEven.py'.
Hint: make sure your test modules/packages have valid Python names.
Traceback:
/nix/store/f98g7xbckgqbkagdvpzc2r6lv3h1p9ki-python3-3.11.9/lib/python3.11/importlib/__init__.py:126: in import_module
return _bootstrap._gcd_import(name[level:], package, level)
tests/test_oddEven.py:1: in <module>
from src.oddEven import oddEven
E ImportError: cannot import name 'oddEven' from 'src.oddEven' (/home/runner/ATD2024trialjl/src/oddEven.py)
---------- coverage: platform linux, python 3.11.9-final-0 -----------
Name Stmts Miss Cover
-------------------------------------------
src/__init__.py 0 0 100%
src/oddEven.py 0 0 100%
tests/__init__.py 0 0 100%
tests/test_oddEven.py 6 5 17%
-------------------------------------------
TOTAL 6 5 17%
=========================== short test summary info ============================
ERROR tests/test_oddEven.py
!!!!!!!!!!!!!!!!!!!! Interrupted: 1 error during collection !!!!!!!!!!!!!!!!!!!!
1 error in 0.16s
>>>>>>>>>>>>>
GENERATE CODE
Planning to change ./src/oddEven.py based on tests in ./tests/test_oddEven.py
Attempt 1
Starting new conversation
Attempting to generate new code with LLM
LLM generated a new ./src/oddEven.py. Passing over to tests in ./tests/test_oddEven.py
RUN TESTS
Running tests (checks) from ./tests/test_oddEven.py
Pytest exited with: 0
TESTS PASS
Code generated and checked
All tests in ./tests/test_oddEven.py passed
Coverage for ./src/oddEven.py: 88%
COMMIT CHANGES (info from git)
Attempting to commit changes
[main 705a712] AI generated changes to ./src/oddEven.py to pass tests in ./tests/test_oddEven.py
1 file changed, 3 insertions(+), 8 deletions(-)
Your tests, and the generated source, have been committed to the repository
ENDING MESSAGE
Code in ./src/oddEven.py is ready for inspectionExtending
- Edit the config section if you want to change the template or model in use.
- Use
./refactorCodeAndCheck.sh «target code file name»to refactor the file in some vague way. Currently experimental.
Using pytest and coverage
Run pytest with pytest «filePathAndName». If your shell is (as it starts) in the directory that contains tests, that's pytest "./tests/test_thing.py".
Add --cov to measure coverage metrics i.e. `pytest --cov ./tests/test_thing.py, then coverage report "./src/thing.py" to see what statements have been covered.
Here are two examples of test files:
Here's a file, in /tests, called test_oddEven.py
from src.oddEven import oddEven
import pytest
def test_oddEven():
assert "even" == oddEven(2)This finds a module (i.e. a python file) src/oddEven.py and imports (makes available) the function it contains oddEven . It imports the test harness pytest. It sets up a group of tests (by defining a function) called test_oddEven , which contains one assert which sends 2 to the oddEven function and expects even back. Pytest will call test_oddEven itself, as it calls all functions that start with test_.
import pytest
from src.oddEven2 import oddEven
expected_even = [2, 0, -4, 100, 1000, "2"]
@pytest.mark.parametrize("number", expected_even)
def test_even_numbers(number):
assert "even" == oddEven(number)
@pytest.mark.parametrize("input_value, expected_output", [
(0.1, "not an integer"),
("A", "not a number"),
("", "empty input"),
])
def test_special_cases(input_value, expected_output):
assert expected_output == oddEven(input_value)
This demonstrates two ways of parameterising tests – the first where the data is a list called number , all of which have the same expected output. The second is a list of pairs of input_value : expected_output, each to be compared by the assert once the input has been transformed by the target function.
Change control / git
Open a Git tab in Replit to have access to git.
The script is aggressive and opinionated. It throws away the old code; if the tests pass, it commits the change, and if they fail it leaves the broken code in place. To go back to the previous commit, you can "discard" the change from the "git" tab
Note that Replit has history which can be rewound: it's finer grained and more accessible. It's not kept permanently.
For a more-familiar interface, you can link your Replit to your gitHub account and push the Replit repo to git.
LLMs in use
Your replit is set up to use two LLMs. Check they can be reached with ./checkClaudeAccessible.sh and ./checkOpenAIAccessible.sh
Instructions
Work in groups of 2-4 unless you prefer to work alone. It will be handy if one or more people in each group can read Python. You may need to re-shuffle to make that happen: if all your group are Python-aware, consider scattering.
Then...
- Get online
- Go to one of:
- https://replit.com/@workroomprds/ATD2024env01
- https://replit.com/@workroomprds/ATD2024env02
- https://replit.com/@workroomprds/ATD2024env03
- https://replit.com/@workroomprds/ATD2024env04
- Fork it
- Sign up to fork the repl – use a burnable email if you like.
- Have a look at Using Replit in the materials folder above
- Identify the file browser, open a shell tab.
- Do Exercise 0
Exercises
We'll do 0, 1 in order.
We imagine that you'll choose either 2 or 3, then 4, 5 – or something else – depending on your interests.
Exercise 0 – Odd and Even
Use the left-hand pane to make a new file, in /tests, called test_oddEven.py
You can edit it in the middle pane. Put this in it.
from src.oddEven import oddEven
import pytest
def test_oddEven():
assert "even" == oddEven(2)oddEven from a file (also called a module) src/oddEven and picks up the test harness pytest. It contains one test group test_oddEven that runs one assert which sends 2 to the oddEven function and expects even back.Open a "shell" tab in the right-hand pane (use the + to get a new tab).

Run the shell script ./makeNewFromTests.sh oddEven.py to generate code. It will generate /src/oddEven.py
The script outputs text to the commandline – see above for an annotated example. See "under the hood" for a diagram and for the code. It makes a new, empty oddEven.py, runs the tests (which fail), generates code, runs the tests (which pass), then commits code and tests before exiting
Exercise 1 – explore and extend oddEven
Hands-on Explorers: Use main.py or the "Run" button to work with the input. What can you see that you'd like to be different?
Code Perturbers: Try messing with the checks. What surprises can you spring – and what surprises you?
Others: Add these new asserts, one by one. After each, run pytest test_oddEven.py to see what fails. Then run the generation script to see how the code changes:
assert "odd" == oddEven(1) assert "not an integer" == oddEven(0.1) assert "not a number" == oddEven("A") assert "empty input" == oddEven() assert "empty input" == oddEven("") assert "empty input" == oddEven(None) assert "odd" == oddEven("1")Note
- these follow the pattern
assert expectation is outcome. - You can put all these in the same
def test_whatever, or each in their own. The names of your functions will be a powerful part of your prompt to the AI.
Extending...
- Try more values – 1e5, "1e5", "1 " and " 1", -5, etc
- Try deleting all the code, and building from all the tests in one go.
- Try switching to a parameterised test.
- Try adding a commented-out test, or adding comments to your test...
A parameterised test might look like:
import pytest
from src.oddEven2 import oddEven
expected_even = [2, 0, -4, 100, 1000, "2"]
expected_odd = [1, -3, 5, 99, 1001, "1"]
@pytest.mark.parametrize("number", expected_even)
def test_even_numbers(number):
assert "even" == oddEven(number)
@pytest.mark.parametrize("number", expected_odd)
def test_odd_numbers(number):
assert "odd" == oddEven(number)
@pytest.mark.parametrize("input_value, expected_output", [
(0.1, "not an integer"),
("A", "not a number"),
("", "empty input"),
(None, "empty input"),
])
def test_special_cases(input_value, expected_output):
assert expected_output == oddEven(input_value)
def test_oddEven_no_argument():
assert "empty input" == oddEven()You can run the tests (without generating code) with `pytest ./tests/test_oddEve
n2.py`.
Maybe see what happens if you delete the code that's been made so far, and start fresh with this collection of 16 tests.
Exercise 2 – Roman numerals
In this, we'll build a common Kata to convert to Roman numerals. Start with the following in /tests/test_romanNumerals.py.
from src.romanNumerals import romanToArabic, arabicToRoman
import pytest
def test_romanToArabic():
assert romanToArabic("I") == 1
def test_arabicToRoman():
assert arabicToRoman(1) == "I"Run ./makeNewFromTests.sh romanNumerals.py
Go have a look at ./src/romanNumerals.py
... we'll compare the different things that the AI has generated, and talk about what that means.
Other people's code
Some examples code that has recently bee suggested in response to these tests...
#!/usr/bin/env python3
def romanToArabic(roman):
roman_values = {
'I': 1,
'V': 5,
'X': 10,
'L': 50,
'C': 100,
'D': 500,
'M': 1000
}
total = 0
prev_value = 0
for char in reversed(roman):
current_value = roman_values[char]
if current_value >= prev_value:
total += current_value
else:
total -= current_value
prev_value = current_value
return total
def arabicToRoman(arabic):
roman_numerals = [
('M', 1000),
('CM', 900),
('D', 500),
('CD', 400),
('C', 100),
('XC', 90),
('L', 50),
('XL', 40),
('X', 10),
('IX', 9),
('V', 5),
('IV', 4),
('I', 1)
]
result = ''
for symbol, value in roman_numerals:
while arabic >= value:
result += symbol
arabic -= value
return result#!/usr/bin/env python3
def romanToArabic(roman_numeral):
"""Convert a Roman numeral to an Arabic number."""
roman_values = {
'I': 1,
}
return roman_values[roman_numeral]
def arabicToRoman(number):
"""Convert an Arabic number to a Roman numeral."""
roman_symbols = [
(1, 'I'),
]
for value, symbol in roman_symbols:
if number == value:
return symbol
return ""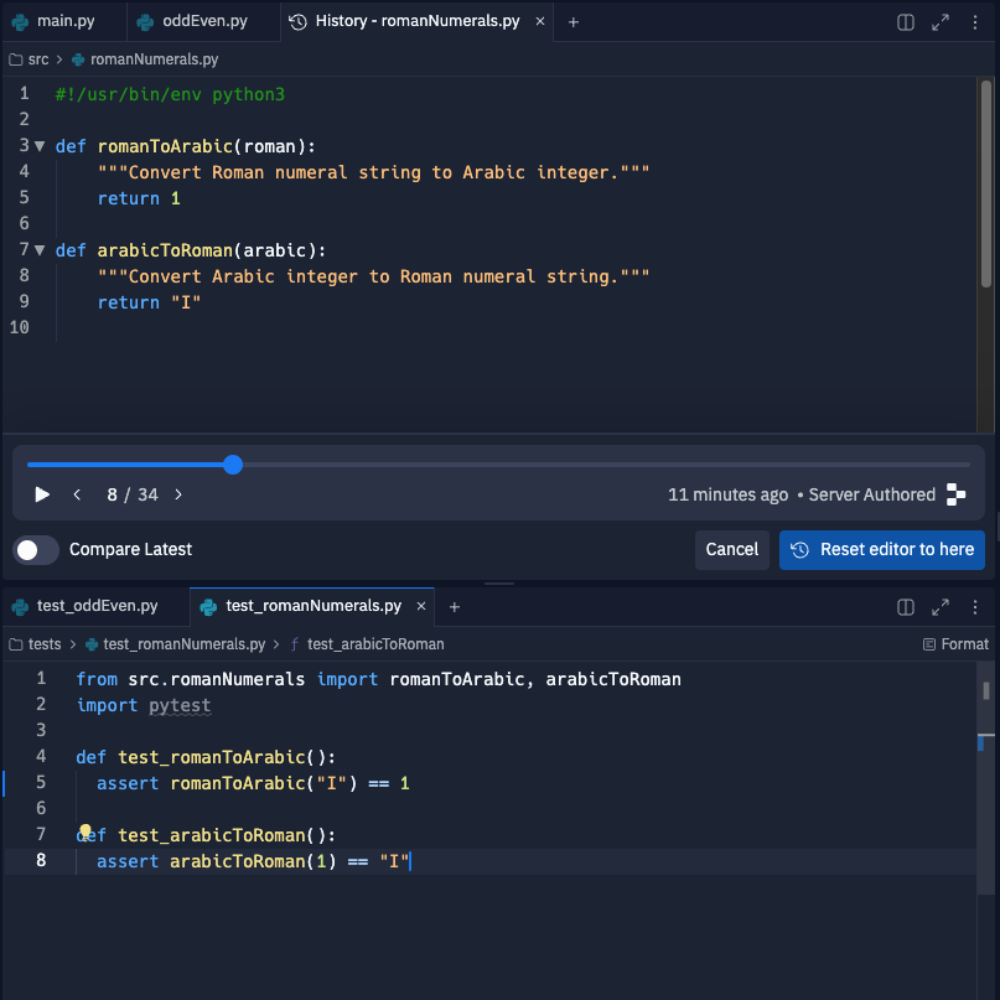
Exercise 3b – Fluvian numerals
Let's imagine that we're in a parallel, six-fingered, Fluvian Empire reality. In the Fluvian Empire, 1 is A, 6 is D, 2x6 = 12 is B, 6x12 = 72 is H, 12x12 = 144 is P, 6x12x12 = 864 is G, 12x12x12 is N.
2 is AA, 3 is AAA, 4 is AAD, 5 is AD, 7 is DA.
OMG.
Start with...
in ./tests/test_fluvianNumerals.py
from src.fluvianNumerals import fluvianToArabic, arabicToFluvian
import pytest
def test_fluvianToArabic():
assert fluvianToArabic("A") == 1
def test_arabicToFluvian():
assert arabicToFluvian(1) == "A"Perhaps we should concentrate on just one, and parameterise?
from src.fluvianNumerals import fluvianToArabic, arabicToFluvian
import pytest
@pytest.mark.parametrize("arabic, fluvian", [
(1, "A"),
(6, "D"),
(12, "B"),
])
def test_fluvianToArabic(arabic, fluvian):
assert fluvianToArabic(fluvian) == arabic...let's talk about what we've seen.
You'll need to explore. main.py may need to be changed so that the fluvian number option reflects the function names that have been generated. There's no need to write code to do this – you can ask Replit's AI, which makes a good attempt, or fire it at a tool you know. It's hacked together code; use the AI to hack something together, and check it. Once you can play, go play!
Add more tests, and let's see how we all get on.
Exercise 3 – Easter
In this, we'll build a tool to generate Easter dates – we'll give it a year, and it'll return the date of Easter Sunday. Start with the following in /tests/test_festival.py
from src.festival import festival
from src.festival import FESTIVAL_WESTERN
from datetime import date
import pytest
# List of festivals between 1990 and 2050
western_festival_dates = [
date(2023, 4, 9),
date(2024, 3, 31),
date(2025, 4, 20)
]
@pytest.mark.parametrize("festival_date", western_festival_dates)
def test_festival_western(festival_date):
assert festival_date == festival(festival_date.year, FESTIVAL_WESTERN)
Have you mentioned Easter? No? Good. Build code to pass these tests with ./makeNewFromTests.sh festival.py
Compare with others.
Try with other dates... or with other festivals.
Easter dates
```
western_festival_dates = [
date(1990, 4, 15),
date(1991, 3, 31),
date(1992, 4, 19),
date(1993, 4, 11),
date(1994, 4, 3),
date(1995, 4, 16),
date(1996, 4, 7),
date(1997, 3, 30),
date(1998, 4, 12),
date(1999, 4, 4),
date(2000, 4, 23),
date(2001, 4, 15),
date(2002, 3, 31),
date(2003, 4, 20),
date(2004, 4, 11),
date(2005, 3, 27),
date(2006, 4, 16),
date(2007, 4, 8),
date(2008, 3, 23),
date(2009, 4, 12),
date(2010, 4, 4),
date(2011, 4, 24),
date(2012, 4, 8),
date(2013, 3, 31),
date(2014, 4, 20),
date(2015, 4, 5),
date(2016, 3, 27),
date(2017, 4, 16),
date(2018, 4, 1),
date(2019, 4, 21),
date(2020, 4, 12),
date(2021, 4, 4),
date(2022, 4, 17),
date(2023, 4, 9),
date(2024, 3, 31),
date(2025, 4, 20),
date(2026, 4, 5),
date(2027, 3, 28),
date(2028, 4, 16),
date(2029, 4, 1),
date(2030, 4, 21),
date(2031, 4, 13),
date(2032, 3, 28),
date(2033, 4, 17),
date(2034, 4, 9),
date(2035, 3, 25),
date(2036, 4, 13),
date(2037, 4, 5),
date(2038, 4, 25),
date(2039, 4, 10),
date(2040, 4, 1),
date(2041, 4, 21),
date(2042, 4, 6),
date(2043, 3, 29),
date(2044, 4, 17),
date(2045, 4, 9),
date(2046, 3, 25),
date(2047, 4, 14),
date(2048, 4, 5),
date(2049, 4, 18),
date(2050, 4, 10)
]
```
Exercise 4 – Build something from your own tests
You've done this a couple of times – try building something of your own.
An LLM is a language model, not a test parser: to get to good code, using the right language may be more as important than introducing the right tests at the right time. This makes sense: TDD is a useful practice within a shared context. You may find that, when you use good names and indicate the expected structure of data, you get to passing tests more easily.
On the other hand, rigid tests are more important than language in getting the code to stay within the limits of behaviour.
With this script, don't expect the AI to generate several interacting source files at once. You can probably build something that has dependencies on existing source files.
If you go for a known Kata, be aware that various solutions will already be in the generator's learned / compressed information. We've seen this with TicTacToe, with Easter calculations and more. I'll be interested to hear what the generators do, if you write a test_gildedRose.py and include a check that the quality of AgedBrie goes up.
Ask the Replit AI (if available on your plan) to add an interface to your code in main.py , or hack around one of the ones you've got. Exploration can be very much helped by a swift response from your own action, and can be hampered by putting a temporary test into code.
Exercise 5 – Change the prompts
AIs aside, this is all tweakable. Change the script to work with different AIs (Claude or ChatGPT) by switching the comment on a line in the config (currently lines 8 and 9).
You can easily change the prompt in use by doing llm templates edit rewrite_python_to_pass_tests, or by setting a new prompt and switching to your new one in the script. Go at it to see what happens.
Note that the command-line instruction above will ask you to edit in vi or nano, but you can open the template directly in Replit's file editor, on path `.config/io.datasette.llm/templates`
Come to that, you can change the system prompt, change the script, use the experimental refactoring tool, and generally think about all the interesting ways you can integrate swift, deterministic tools with fuzzy, fast generation, and your own wise and perceptive brain.
Exercise 6 – Pathfinder
Here is a set of tests, and the resulting code. The tests set up a simple network of connected elements, then ask for (and expect) the shortest (fewest points, fastest time, lest distance) route.
The code and tests were built in parallel, with tests generally being introduced top-to-bottom. One wrinkle is that the points were initially ("A", "B").
The generator built a depth-first search (without being asked explicitly), and can extract routes from larger networks – there's an exploratory tool that sets up random networks to play with. I'll post it when I find it.
from src.routeFinder import findRoute, makep2p
import pytest
def test_routeFinder():
assert callable(findRoute)
assert callable(makep2p)
def test_makep2p():
assert ("A", "B") == makep2p("A", "B", 5, 10).step
assert 5 == makep2p("A", "B", 5, 10).distance
assert 10 == makep2p("A", "B", 5, 10).duration
#default distance
assert 1 == makep2p("A", "B", None, 10).distance
#default duration
assert 60 == makep2p("A", "B", 5, None).duration
def test_two_point_route(): #should return a list of lists
routes = [makep2p("A", "B"), makep2p("B", "C")]
assert findRoute(routes, "A", "B").allRoutes == [["A", "B"]]
assert findRoute(routes, "B", "A").allRoutes == [["B", "A"]]
assert findRoute(routes, "B", "C").allRoutes == [["B", "C"]]
def test_three_point_route():
routes = [makep2p("A", "B"), makep2p("B", "C")]
assert findRoute(routes, "A", "C").allRoutes == [["A", "B", "C"]]
assert findRoute(routes, "C", "A").allRoutes == [["C", "B", "A"]]
def test_route_offers_alternatives():
routes = [makep2p("A", "B"), makep2p("B", "C"), makep2p("A", "C")]
assert len(findRoute(routes, "A", "C").allRoutes) == 2
assert ["A", "C"] in findRoute(routes, "A", "C").allRoutes
assert ["A", "B", "C"] in findRoute(routes, "A", "C").allRoutes
#the route with the smallest aggregate distance
assert ["A", "C"] == findRoute(routes, "A", "C").fewestStops.route
def test_calculates_distance():
routes = [makep2p("A", "B", 2, 20), makep2p("B", "C", 3, 30)]
assert ["A", "B", "C"] == findRoute(routes, "A", "C").fewestStops.route
assert 5 == findRoute(routes, "A", "C").fewestStops.distance
def test_calculates_duration():
routes = [makep2p("A", "B", 2, 40), makep2p("B", "C", 3, 30)]
assert ["A", "B", "C"] == findRoute(routes, "A", "C").fewestStops.route
assert 70 == findRoute(routes, "A", "C").fewestStops.duration
def test_calculates_shortest_distance():
routes = [makep2p("A", "B", 2, 20), makep2p("B", "C", 3, 30), makep2p("A", "C", 10, 100)]
assert ["A", "B", "C"] == findRoute(routes, "A", "C").minDistance.route
assert 5 == findRoute(routes, "A", "C").minDistance.distance
routesShortAtoC = [makep2p("A", "B", 2, 20), makep2p("B", "C", 3, 30), makep2p("A", "C", 4, 40)]
assert ["A", "C"] == findRoute(routesShortAtoC, "A", "C").minDistance.route
assert 4 == findRoute(routesShortAtoC, "A", "C").minDistance.distance
def test_calculates_smallest_duration():
routes = [makep2p("A", "B", 2, 20), makep2p("B", "C", 3, 30), makep2p("A", "C", 10, 100)]
assert ["A", "B", "C"] == findRoute(routes, "A", "C").minDuration.route
assert 50 == findRoute(routes, "A", "C").minDuration.duration
routesShortAtoC = [makep2p("A", "B", 2, 20), makep2p("B", "C", 3, 30), makep2p("A", "C", 4, 40)]
assert ["A", "C"] == findRoute(routesShortAtoC, "A", "C").minDuration.route
assert 40 == findRoute(routesShortAtoC, "A", "C").minDuration.duration
def test_longer_route():
routes = [
makep2p("A", "B"),
makep2p("B", "C"),
makep2p("A", "C"),
makep2p("C", "D"),
makep2p("D", "E"),
makep2p("E", "F")
]
assert ["A", "C", "D", "E", "F"] in findRoute(routes, "A", "F").allRoutes
def test_errors():
assert makep2p(None) == "ERROR: no routes supplied to makep2p"
assert makep2p([]) == "ERROR: no routes supplied to makep2p"
assert findRoute(None, "A", "B") == "ERROR: no routes supplied"
assert findRoute([], "A", "B") == "ERROR: no routes supplied"
assert findRoute([makep2p("A", "B")], "C",
"B") == "ERROR: start point is not in routes"
assert findRoute([makep2p("A", "B")], "A",
"C") == "ERROR: end point is not in routes"
assert findRoute(
[("A", "B"), ("C", "D")], "A",
"D") == "ERROR: there is no connection between start and end"
#!/usr/bin/env python3
from typing import List, Tuple, Optional, Union
from dataclasses import dataclass
@dataclass
class Point2Point:
start: str
end: str
distance: float = 1
duration: float = 60
@property
def step(self) -> Tuple[str, str]:
return (self.start, self.end)
def makep2p(start: str, end: Optional[str] = None, distance: Optional[float] = None, duration: Optional[float] = None) -> Union[str, Point2Point]:
if not start or not end:
return "ERROR: no routes supplied to makep2p"
return Point2Point(start, end, distance or 1, duration or 60)
@dataclass
class Route:
path: List[Point2Point]
@property
def route(self) -> List[str]:
return [p.start for p in self.path] + [self.path[-1].end]
@property
def distance(self) -> float:
return sum(p.distance for p in self.path)
@property
def duration(self) -> float:
return sum(p.duration for p in self.path)
@dataclass
class RouteResult:
all_routes: List[Route]
@property
def allRoutes(self) -> List[List[str]]:
return [route.route for route in self.all_routes]
def _min_route(self, key_func):
return min(self.all_routes, key=key_func) if self.all_routes else None
@property
def shortestRoute(self) -> Optional[Route]:
return self._min_route(lambda r: r.distance)
@property
def fewestStops(self) -> Optional[Route]:
return self._min_route(lambda r: len(r.route))
@property
def minDistance(self) -> Optional[Route]:
return self.shortestRoute
@property
def minDuration(self) -> Optional[Route]:
return self._min_route(lambda r: r.duration)
def create_route_map(routes: List[Union[Point2Point, Tuple[str, str]]]) -> Tuple[set, dict]:
all_points = set()
route_map = {}
for route in routes:
if isinstance(route, Point2Point):
p2p = route
elif isinstance(route, tuple):
p2p = Point2Point(route[0], route[1])
else:
raise ValueError("Invalid route type")
all_points.update(p2p.step)
route_map.setdefault(p2p.start, []).append(p2p)
route_map.setdefault(p2p.end, []).append(Point2Point(p2p.end, p2p.start, p2p.distance, p2p.duration))
return all_points, route_map
def dfs(start: str, end: str, route_map: dict) -> List[List[Point2Point]]:
def dfs_recursive(current: str, path: List[Point2Point], visited: set):
if current == end:
yield path
for route in route_map.get(current, []):
next_point = route.end
if next_point not in visited:
yield from dfs_recursive(next_point, path + [route], visited | {next_point})
return list(dfs_recursive(start, [], {start}))
def findRoute(routes: List[Union[Point2Point, Tuple[str, str]]], start: str, end: str) -> Union[str, RouteResult]:
if not routes:
return "ERROR: no routes supplied"
all_points, route_map = create_route_map(routes)
if start not in all_points:
return "ERROR: start point is not in routes"
if end not in all_points:
return "ERROR: end point is not in routes"
all_routes = dfs(start, end, route_map)
valid_routes = [Route(route) for route in all_routes if route[-1].end == end]
if not valid_routes:
return "ERROR: there is no connection between start and end"
return RouteResult(valid_routes)
__all__ = ['findRoute', 'makep2p']
Sharing at the End
In groups, decide something that you have to share. Perhaps it's a vital insight, a direct experience, or perhaps it's comedy gold. We'll go round for those first.
Individually, identify some way that you personally have changed over the last 90 minutes. We'll go round for those second.
Under the Hood
Surprises...
This is not an exhaustive list
- Generators don't notice commented-out tests
- Given inconsistent tests, generators go wild
- Generators pay more attention to names and to comments in test files than to the tests (which can be handy)
- Generators are not deterministic (this shouldn't be a surprise) and can produce several different approaches to the code: Example – when calculating Easter, generators can take a path to have specific dates, or to perform a generic calculation – and can switch paths.
- Generators wrap their code in ```python , prefix with
here's the code you need. The prompts avoid this, but it might be better to ask for code wrapped in tags, and extract it. - Generators produce more code than is tested, typically because you've asked for something in the training data. Example: try using a code Kata.
- Generators don't know libraries, and might code something explicitly rather than using the right library, or even the right native function (James saw a generator build a bubble sort, rather than using
sort(. Or they might use libraries, and not tell you that the library is needed. - Generators make mistakes. Example: using a module that has not been viably imported. With iteration, these tend to get fixed. Like humans, sometimes the generator needs feedback from running the code.
Script: `makeNewCodeFromTests.sh`
You make your changes to a file of tests, and run a commandline script.
The script takes in a single parameter: the name of the file that is to be re-generated. Using that name, it grabs (your) test file, tests the code, and gives your tests, the existing code, and the test results to an AI, with instructions to change the code.
The script takes the AI's output, replaces the code, re-runs the tests and repeats until the tests pass, or until it's tried enough.
If the test pass, the script commits the code.
Script Diagram
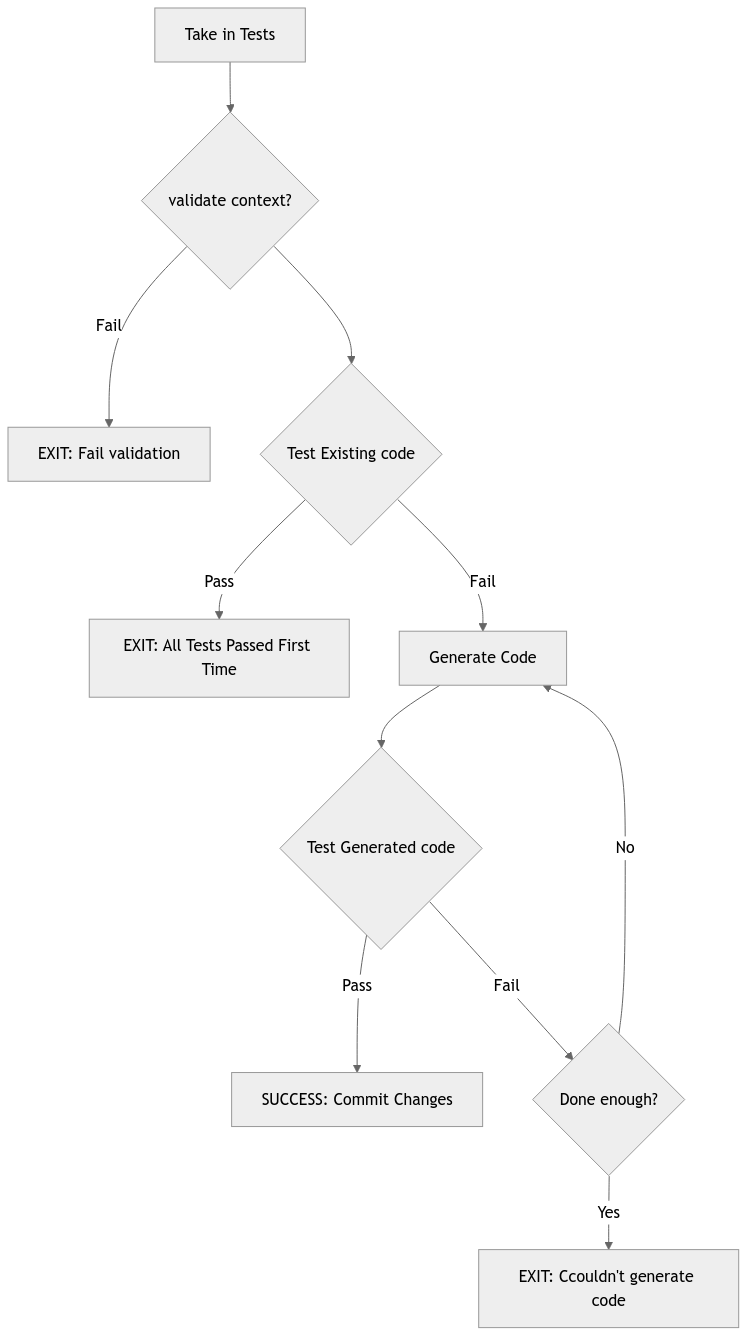
Script
This is direct from github... but is it the right github?
ScriptFromGitHub
AI Prompt
model: claude-3.5-sonnet
name: rewrite_python_to_pass_tests
prompt: Starting from Python code in $code, output that code with changes to pass tests described in $tests. Please note that the code currently fails the tests with message $test_results. Your output will be used to replace the whole of the input code, so please output ONLY code. Ensure the code starts with a valid Python statement or definition, not with any kind of greeting or explanation.
system: "You are expert at Python. You can run an internal python interpreter. You can run pytest tests. You are methodical and able to explain your choices if asked. You write clean Python 3 paying attention to PEP 8 style. Your code is readable. When asked for ONLY code, you will output only the full Python code, omitting any precursors, headings, explanation, placeholders or ellipses. Output for ONLY code should start with a shebang. If you need to give me a message, make it a comment in the code."
Background: How we learned and worked
For this workshop, we knew that we had taken on a subject that was technologically interesting, and (as usual) outside our technical abilities. We had several false starts on the tech, and got bogged down in local models, AI APIs and python configuration,.
The llm library abstracted away plenty of the AI wrangling, and once adopted, got us to a proof of concept in hours. We moved to cloud-hosted AI and IDE, which allowed us to offer the experience to people not actually sitting at James' laptop.
Along the way, we had a long, unproductive and expensive journey with gitPod. Replit is not sustainable in the longer term, and we'll probably go back to Ansible and Docker, if we can find a viable IDE for the browser...
We built and explored, picking up pitfalls and trying to reduce the non-AI-related ones. We settled on exercises that – we hoped – let participants experience key moments from our learning. We talked every few weeks – a little less than on prior occasions.
James found that doing the work gave him more insight into how AIs work, confirming that as language models they pay as much (and maybe more) attention to the context of names and comments as to examples. He re-discovered bash ( helped by an AI which ably (if not reliably) suggested options and explained code), and was pleased to get deterministic tools working with AI. Some further steps would be to take this into a multi-agent setup; asking AIs with different prompts to work together.
The biggest and strangest learning was around TDD – which to this point has felt safe, flow-enabling and design focussed. It is a key technique for James when building pure functions in code for tools and games. However, when compared with the ease of exploring solutions by asking for code in natural language, it now feels somehow forced or restrictive. This was best illuminated in practice by comparing the feeling of a) trialling the exercises with b) using AI to knock up co-build main.py and the shell scripts. Going forward, James expects that he'll still employ TDD when building long-lasting core functions and shared utilities, while using AI to throw together ephemeral tools to assist in exploring i.e. short-lived interfaces, data analysis, data generation.
Last time, we identified several ways that we approached learning. Here's the list for 2024.
- AI-Assisted (new for 2024) – Ask an LLM to explain a concept or a technical wrinkle.
- Authority-first – follow the book, ask the expert
- Promise-driven – commit to do something you don't know how to do,
- Confusion-driven – try to understand the part you recognise as a part, yet understand the least
- Foundation-driven – work from what you already know, and expand outwaerds
- Literature survey – what are the key words? Go search, building a collectioon of core vocabulary (words and concepts). Do they mean different thigns to different groups? What are the core articles / sites / authors / groups / magazines / books / exercises / metaphors?
- Ask publicly for help – get comfortable with your own ignorance and curiosity, attract people who want to help, reward their commitment with your progress.
- Aim to teach / write – teaching and writing both require your mind to enage with the subject in a reflective, more-disciplined way
- Value-driven – find and deliver something of value to someone
- Trial-and-error – thrash about, reflect on what happened, repeat with control, thrash more.
Read about using an LLM to help your learning – with examples from this workshop.
Read about James's current LLM tech stack.